


Holy Grail and AI Core Values
As is obvious from the messages posted in AI-related teacher support groups, automated grading is, for many, the Holy Grail of AI integration.
As a former teacher, I can certainly understand why. It is not only the hundreds of pages of student work that have to be read, but also the internal struggle over the appropriate “scores” to give them based on generic rubrics.
Yet, despite my interest in the potential of AI technologies in education, this particular application was never a focus of mine. For many different reasons, I used to believe that AI assistance could be appropriate to provide formative feedback, but not summative grades. These reasons included:
Lack of reliability : AI grading can only be inconsistent, due to the generative nature of LLMs.
Lack of accuracy: AI cannot assess abstract competencies. Even though LLMs were trained to follow instructions, assigning quantitative scores to student works based on qualitative rubrics is a highly-complex and specific task they were never prepared for.
Lack of relationship: Even if it could be made reliable and accurate, AI grading would mean the loss of an important way teachers get to know their students and build connections with them.
Skill loss: By delegating grading to AI, teachers would lose familiarity with the targeted demonstration of learning that should guide instruction.
Lack of agency, (or transparency): Using AI to grade, teachers would model poor use of this technology to their students by entrusting it with final decision-making and relinquishing their own thinking and responsibility. Or, even worse, they would not be transparent about it.
Technical Trial and Discovery Process
Such was my mindset when my friend Pascal Vallet shared with me, in preparation for one of our podcasts, the work he had been doing on AI grading reliability (or lack thereof).
Pascal’s research showed just how much variation there was in the iterative assessment of identical essays, using identical rubrics, within and across language models; and I saw this as a challenge and an interesting problem to try and solve. Having no interest in any potential application at the time, since I was opposed to AI grading out of principle, this was really just a pretext to learn and apply different techniques that could potentially serve other purposes (e.g., using structured outputs, or the LiteLLM framework).
What followed was an ongoing conversation and experimentation that changed my mind - to an extent - as I realized:
That “vanilla” AI grading is so bad - but so tempting, that an advanced version might still be desirable and help avoid a worst-case scenario.
That the ways AI grading can be improved are in fact ways AI can assist (and enhance) human grading.
That I was therefore wrong to think of “AI grading” as a black-and-white situation where teachers either delegate grading to AI entirely, or do it completely by themselves, unaided. I now think that “AI grading” can be an example of “co-intelligence”, to use Ethan Mollick’s expression, where AI is used as an assistant in a broader process.
Vanilla AI Grading
The starting point was to try and replicate the problem identified by Pascal, and by doing so to assess the basic way most teachers would likely grade an essay using generative AI: feeding a rubric, an essay, and a simple prompt to gpt-4o-mini.
As can be seen in the graph below, the variation across 10 runs was indeed quite high, total grades ranging from 18/50 to 27/50.
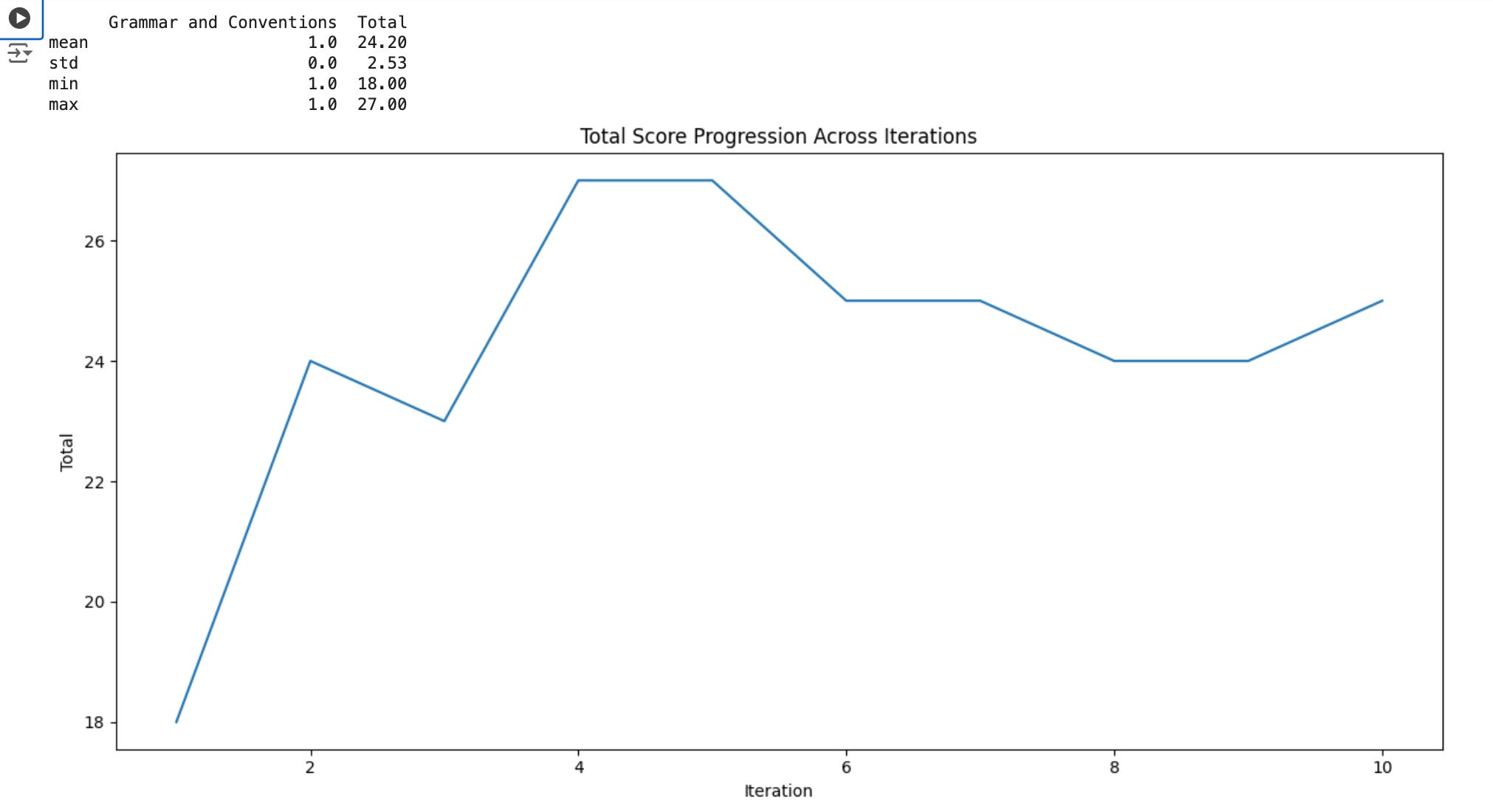
As expected, the most abstract and complex categories, “Understanding of Content” and “Comparative Analysis”, had the most variation, the latter oscillating between 4/15 and 8/15. Comparatively, Organization and Structure, Use of Sources and Evidence, and Grammar and Conventions, seemed easier for AI to evaluate.

This lack of test-retest reliability led me to explore multiple solutions.
One that I found useful (and simple), was to use structured outputs, to ensure greater fidelity to the rubric.
Another, even simpler but actually more effective solution, was then to change the model’s temperature. This greatly increased consistency, the range decreasing from 9 to 3. As a matter of fact, all 10 iterations yielded a 24/50, except for one run at 21

For the initial trial, I had used a temperature of 0.7 (the default on ChatGPT). With a temperature of 0.1 (i.e., more deterministic outputs), category scores were clearly more homogeneous as the model seemed to settle on 10/20 for Understanding of Content and 6/15 for Comparative Analysis.

Consistency and Accuracy
However, consistency (or precision) does not equal accuracy. AI grading can be consistently off-mark - and this seemed to be the case here.

A total grade of 24/50 and a 10/20 for Understanding seemed (to the former Humanities teacher in me) too high for this essay, which systematically confused two ancient civilizations.
As I realized, lowering the temperature did not fix the root of the issue, which came not only from the limitations of generative language models, but from their conflation with the limits of the rubric itself.
Like most rubrics, it included ranges such as:
Understanding of Content (20 points)
- Level 4 (16-20): Thorough understanding
- Level 3 (11-15): Good understanding
- Level 2 (6-10): Basic understanding with some inaccuracies
- Level 1 (0-5): Limited understanding, inaccurate information
The problem here is that:
1) The difference between a “limited” and a “basic”, or a “good” and a “thorough” understanding can only be subjective, unless it is further detailed with explicit criteria and/or examples.
The reason why those are often missing is because:
2) It would be quite difficult to come up with 5 truly distinctive levels within “Basic understanding”.
Importantly, these are issues that exist for human graders as well as for AI graders. The difference is that it is impossible to compare a teacher’s iterative evaluations of the same essay. But given the lack of clarity around what consitutes a “basic understanding” of a topic, it would not be surprising if the selection of a specific score by a human grader depended on other factors - including biases.
Reliability and Information
Consistency and accuracy are two important dimensions of measurement in natural sciences, but information is a critical third element in assessment and in educational science.
It would be quite easy to create a rubric that would yield reliable grades. For instance:
Language
Is the essay written in English?
Yes = 100%
No = 0%
But such an assessment would not be informative at all about the qualities of the essay and the competencies demonstrated by the student.
And as we make a rubric more informative, with more categories, levels of performance, and ranges of scores, we also make it less straightforward - and therefore grades less reliable.
Advanced AI Grading
The final workflow I devised aimed to solve this problem. As described in the diagram below:
First, an LLM (gpt-4o-mini) assessed a series of essays with a rubric, as well as a human example of the application of this rubric.
As it does so, the LLM stores its comments such as “This essay accurately identifies two ancient civilizations, which is an example of basic undertanding”; “This essay inaccurately describes Ancient Egypt as a democracy, which is an example of a major inaccuracy, and therefore low basic undersranding”.
These comments are then passed to a reasoning model (o1-mini), which turns them into a comprehensive and highly detailed markscheme. Such a markscheme solves two of the issues outlined above:
It does not contain ranges, but unique descriptors for each score within a range.
It also contains, for each of these descriptors, explicit, objective rules, as well as examples to generalize from.
This markscheme is then fed back to 4o-mini, which uses it to grade essays 10 different times each.
Finally, a statistical report is generated, along with a comparison and synthesis of the 10 evaluations.

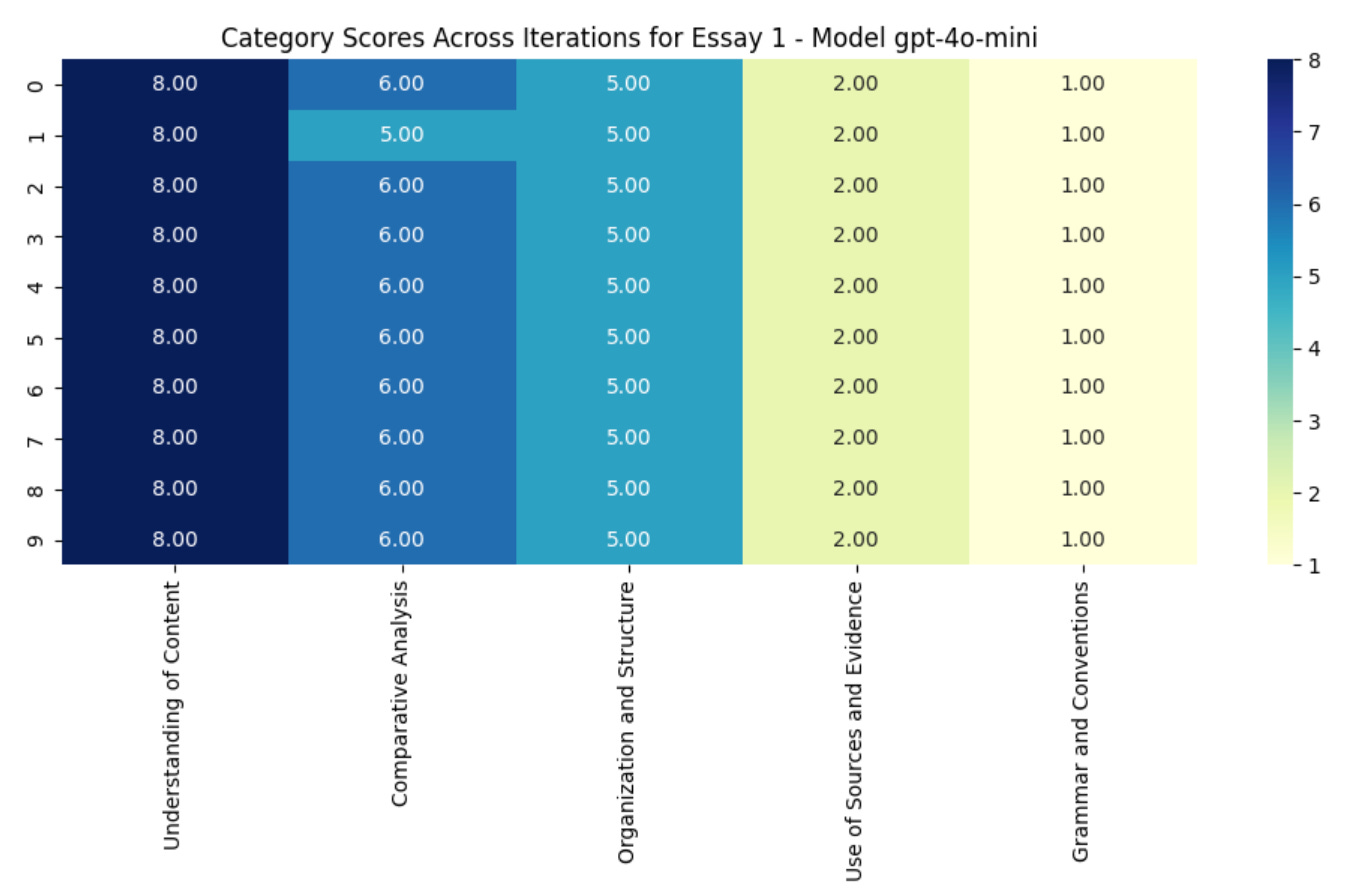
Fron the graph below, we can draw two major lessons:
This workflow made 4o-mini much more consistent, as the range is now limited to 1. Of the 50 category scores generated, there was only one variation (a 5/15 instead of a 6/15 in Comparative Analysis)
The workflow also made 4o-mini more accurate. The two previous experiments gave the essay a majority of 10s in Understanding of Content - the upper limit of “Level 2 (6-10): Basic understanding with some inaccuracies “ in our rubric. This was too high (based on my own judgment), and the change to an 8/20 seems more appropriate, and indeed in line with the markscheme:
8: Limited Understanding
- Limited coverage with major inaccuracies.
- Attempts to cover content but lacks depth and accuracy.

Financial and Environmental Cost
At one point, I ran and synthesized iterative evaluations of multiple models (Claude 3.5, Gemini 2.0, and Deepseek v3). Results demonstrated a persistently and incredibly low inter-rater reliability.
On the one hand, this confirmed my conviction that grading should not be entrusted to AI. On the other hand, this helped me see how AI can assist human grading, and indeed be used to detect potential hallucinations and/or biases.
Each model, due to its particular pre- and post-training data and techniques, shed a unque light on the essay. Distilled into a concise report, these perspectives could equip a teacher with the body of evidence needed to make an expert final decision. This could not only ease, but also potentially enhance the grading process, just like the creation of a markscheme, by facilitating the connection between the detailed wording of the essay and the broad categories of the rubric.
It would also add to the financial and environmental cost of the process - or rather to the actions to (not) take to offset this footprint. We might therefore limit ourselves to 2 cheaper models (such as 4o-mini and Gemini 2.0 Flash). That being said, given the test-retest reliability of the flow, we could also, in production / real cases, use a much smaller number of iterations.
NB. The entire workflow I tested processed around 85,000 input and 15,000 output tokens (depending on the number and length of essays). The total cost (with caches) would therefore be a cent for the one-time markscheme creation, and a tenth of a cent for each additional essay. As for the global footprint, a user could offset it, for instance, by streaming a couple of hours less of Netflix and/or opting for a vegetarian meal that day.
AI-Assisted Co-Grading
For teachers, the flow could look something like this:
Grade one essay with detailed explanations, and feed this evaluation, along with the rubric and all other essays, to gpt-4o-mini.
Use a reasoning model (Gemini 2.0 Flash Thinking) to turn all generated comments into a comprehensive markscheme.
Review the markscheme and edit as needed.
Batch-process the essays again, along with the markscheme (cached), for a few iterations, and generate a synthetic report.
Review the report, and assign appropriate grades.
Note that:
Steps 1, 2, and 3 only have to be done once. The markscheme can then be reused for multiple classes, year after year, and shared with colleagues.
Steps 1, 2, and 4, can be as simple as clicking a button once the app is ready. While the bulk of the code already exists, it still needs a few tweaks, red-teaming, and further testing to be ready to be released: a an easy-to-use UI, a protection against prompt injection, and evaluation for equity.
Steps 3 and 5 are human-in-the-loop stages ensuring human oversight and final decision-making
Best of Both Worlds
While it was initially created as a purely experimental project, and then designed to avoid worst-case scenarios, this workflow might actually help combine the best of both worlds.
Not only does it make grading more efficient, but it also helps make it more consistent, accurate, and informative.
Even more crucially, it does not come with what I used to see as negative consequences necessarily associated with AI grading. Rather than unacceptable trade-offs of automation, I now see those as opportunities to rethink grading in the age of AI assistance:
Relationships: AI-assisted grading does not need to take away from the human connection between students and teachers. Not only does it create a “third point” that can be a basis for discussion, but by making evaluation less subjective, it also helps build psychological safety. This was a major takeaway from a survey conducted by one of our teachers: students reported lower levels of stress and higher levels of proximity with their teachers knowing that their grades were not personal judgments, but based on algorithmic metrics.
Skill Gain: Far from losing familiarity with the targeted demonstration of learning that should guide instruction, this flow helps teachers understand it better by moving from a generic rubric to a comprehensive markscheme.
Agency and AI Literacy: Using AI in this way as part of the grading process, teachers arguably model exemplary AI literacy - by relying on advanced techniques mitigating the limitations of these technologies, and by leveraging their potential to increase the efficiency and enhance the effectiveness of human processes, all while maintainig ultimate responsibility, and offsetting their footprint.
Next Steps
While this workflow is still a few steps removed from being an app ready for beta-launch, as I explained above, alternatives also exist.
One of the reasons vanilla AI grading is so bad is because grading is more akin to a classification task, while the models used were trained for generative purposes. A solution, then, could be to fine-tune models for this specific task.
This is something I have barely started to try. The main hurdle, here, is actually the curation / creation of the dataset (a sufficient number of high-quality grading examples). Hopefully, the workflow above will help - and could be an opportunity for schools around the world to collaborate on this project.
wow, thank you very much, this is fantastic research and I am very interested in its application.